  30.09.2015 18:53 30.09.2015 18:53
Vorlieben-Statistik
von sleepless_lives
|
   |
|
Hier kommt wieder der Blick auf die Texte mit Hinsicht auf Bewertertendenzen. Leider nur für die Prosa, denn bei der Lyrik ist nicht genügend Material vorhanden, um zu einigermaßen verlässlichen Ergebnissen zu kommen. Ich recycle mal für die Erklärung weitgehend das, was ich beim Dichte-Weite-Wettbewerb geschrieben habe:
Es handelte sich um eine statistisches Verfahren, das Bewertungen analysiert. Die Methode heißt MDPREF (Jackson, J.E. (1991). A User's Guide to Principal Components. John Wiley & Sons) und ist Teil einer Gruppe von statistischen Verfahren, die als Multidimensionale Skalierung bezeichnet werden (die Details spare ich uns hier).
Die Methode versucht, rein rechnerisch Faktoren zu bestimmen, die das Verhalten der Bewerter ausgemacht haben, in dem sie Übereinstimmungen und Kontraste im Bewerterverhalten analysiert. Die Faktoren muss man aber selbst interpretieren. Hätten wir 22 verschiedene Schokoladenarten bewertet, hätte sich z. B. herausstellen können, dass der entscheidendste Faktor die Süße <---> Bitterkeit-Achse ist. Leider kann man graphisch nur zwei Faktoren gut darstellen. Den ersten auf der horizontalen Achse, den zweiten auf der vertikalen. Vor mehr Erklärungen hier erstmal die Graphik mit der Legende darunter.
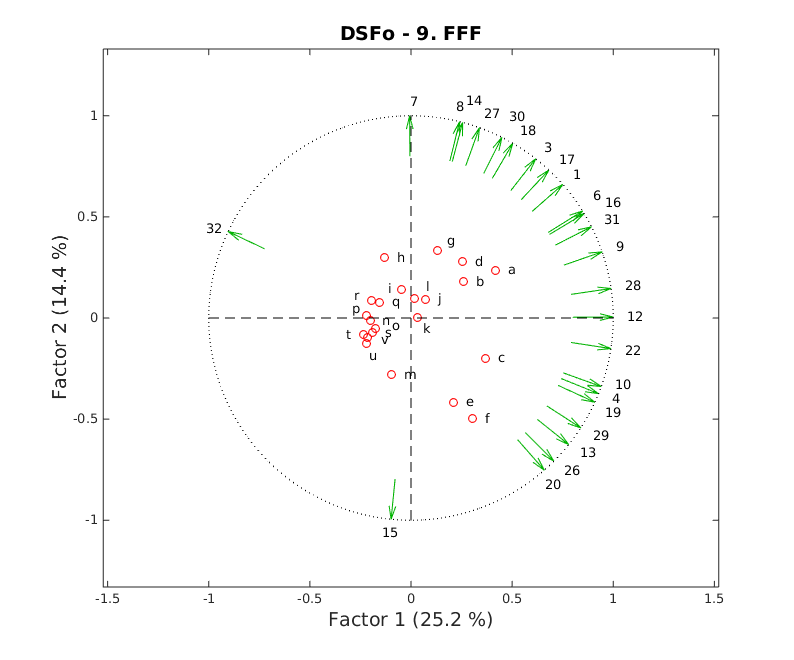
a: Risse 1: Literaettin
b: Fuenf_Stunden
c: Bitterer_Kaffee 3: holg
d: Silberling 4: Michel
e: Im_Inneren
f: Wahrscheinlich_stimmt 6: Ruebenach
g: Tod_in_der_Wueste 7: Merope
h: Abfallzahlen 8: shatgloom
i: In_ungestoerter 9: nebenfluss
j: Also 10: Jenni
k: Logenplatz
l: Lola 12: BlueNote
m: Offenes_Hoffen |
 Login
Login








